


Om du har vært på Internett i det siste kan du umulig ha unngått Facebook-skandalen, hvor brukerdata ble delt med firma og personer som ikke burde fått tilgang. Men hvordan fungerer egentlig data og hva er problemet med Facebook?
En praktisk problemstilling
I stedet for en teknisk forklaring vil jeg heller vise et eksempel fra mitt første virkelige programmeringsprosjekt. Jeg var i 2015 del av fadderstyret ved Universitetet i Bergen og hadde ansvar for å arrangere fadderuken. Universitetet har 17 000 studenter, og en betydelig andel av disse deltar i ukens opplegg.
En av utfordringene vi møtte var hvordan vi skulle fordele studentene. Tidligere hadde de blitt fordelt noenlunde tilfeldig avhengig av studieretning, med varierende resultat. Veldig mange var misfornøyd med gruppen sin eller følte de havnet på gruppe med folk de ikke hadde noe til felles med. Hvordan kunne dette forbedres? Studentene har tross alt ønsker om hvem de skal være på gruppe med, så hva om vi kunne ta høyde for dette?
Innsamling av data
En enkel måte å samle inn slike ønsker på er gjennom et skjema. Vi spurte blant annet om navn, studieretning, og hvem de ville være på gruppe med. Listen med resultat ble etter hvert veldig lang, og hvert eneste svar så ut som dette:
-1.png?width=600&height=198&name=image%20(2)-1.png)
Å gjennomgå flere hundre linjer som ser slik ut er helt umulig. Man mister oversikt etter å ha sett på et par personer, og ikke minst ville det tatt ukesvis å få gjort skikkelig. Dette betyr ikke at det er umulig å ta stilling til studentenes ønsker, men at det ikke er praktisk å gjøre for hånd uten digitale hjelpemidler.
Et sosialt nettverk
Noe av det kraftigste man kan gjøre med programmering er å visualisere data. På mange måter ligner dataene vi samlet på dataene Facebook har om oss. I begge tilfeller har vi en haug med mennesker og relasjoner mellom dem.
Disse relasjonene kan tegnes som en graf, hvor hver person er et punkt og ønsket om å være med noen en strek mellom to punkt. Bildet som følger er en illustrasjon av personene og relasjonene mellom dem fra Universitetet i Bergen i 2015.
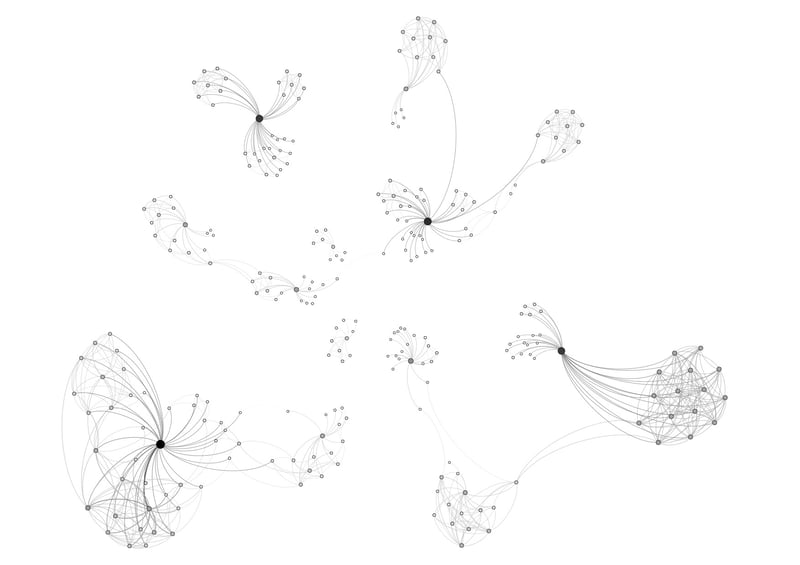
Illustrasjonen viser deltakere i fadderuken som grå punkt, og at to av dem ønsket å være på gruppe som en linje mellom dem. De svarte punktene er studieretninger. Den øverste gruppen til venstre kan dermed tolkes som at den studieretningen har 3 vennegrupper og et par frie sjeler.
Laget av Patrick Monslaup, visualisert i Gephi
Å vise dataene på denne måten gjør at vi veldig raskt kan se trender og detaljer i det som tidligere ville vært vanskelig å tolke. At studentene definerte hvem de ville være med lot oss tegne det sosiale nettverket som eksisterte på universitetet, som vi ellers aldri ville forstått oss på. Vi hadde nå muligheten til å enkelt dele dem opp i grupper basert på deres ønsker.
Med stor makt følger stort ansvar
Jeg liker å tro at følelsen jeg fikk da jeg visualiserte vennskapene på universitetet er litt lik følelsen Mark Zuckerberg fikk da klassekameratene begynte å fylle ut sine profiler på Facebook. Det er utrolig kult å kunne se kompliserte sammenhenger, og enda gøyere når man kan lage noe av det. Verden er full av slike koblinger som vi ikke klarer å se eller forstå fordi mengden data er for stor til å ta stilling til. At programmering gir deg verktøyene du trenger for å tolke verden var intet annet enn magisk for meg.
At jeg har oversikt over vennskap er kanskje ikke et problem, men hva hvis jeg hadde delt en oversikt med bilde og navn? Hva hvis jeg deretter hadde koblet opp og markert personer som har en viss seksuell legning, eller en viss politisk affiliasjon? Du tenker kanskje at dette ikke er et problem eller en sak, men det er en aktuell problemstilling!
Et av mine favoritteksempler på hvordan programmering kan finne sammenhenger andre ikke kan se er fra Target, en dagligvare i USA. De analyserte kundenes kjøpsmønstre, og brukte dette til målrettet reklame. Hvis noen kjøpte en stor bag, teppe og zinksalve så kan man med ganske stor sikkerhet anta at personen venter barn. Basert på slike data ble tilbud på babyprodukter sendt ut, som i dette tilfellet gikk til en 15 år gammel jente. Hun var faktisk gravid, men faren hennes som åpnet posten visste ikke om det før da.
Et voksende problem
Problemet med slik innsikt er når det gjelder sensitive tema, spesielt om man ikke har oppgitt denne informasjonen selv. At en matbutikk kan klare å finne ut at du er gravid sier litt om hvilken innsikt som ligger i kjøpsmønstre og data. Det trenger ikke nødvendigvis å være et problem at en bedrift har slik informasjon, gitt at de ikke misbruker den. Lekkede meldinger fra Mark Zuckerberg i 2004 er som følger:
Zuck: Yeah so if you ever need info about anyone at Harvard
Zuck: Just ask
Zuck: I have over 4,000 emails, pictures, addresses, SNS
[Redacted Friend's Name]: What? How'd you manage that one?
Zuck: People just submitted it.
Zuck: I don't know why.
Zuck: They "trust me"
Zuck: Dumb fucks

Allerede i 2004 var Zuckerberg i besittelse av ekstremt mye sensitiv data. Facebook har i dag fullstendig oversikt over ekstremt mange mennesker liv, uavhengig av om de vet eller ønsker det. Det du ikke legger ut selv kan de finne ut av ved å behandle data, og de leser jo ellers meldingene dine og avlytter telefonsamtaler. Selv om du ikke er meldt opp til Facebook registrerer de hvilke sider du besøker, slik at de har masse informasjon om deg hvis du noensinne melder deg opp.
Facebook har lenge blitt kritisert for dette, og opp gjennom årene har de vært i medier mange ganger fordi de ikke tar personvern seriøst. Dagens problem er at de har delt dataene dine selv om du har bedt dem la være, og at de ikke har slettet deg når du ber om det. Dette har blitt misbrukt av politiske partier fra USA og Russland til å manipulere valg, og er dermed ikke bare et problem for deg som person, men for hele samfunnet og demokratiet.
Å temme dragen
EU så problemet med dette for noen år siden, og brukte fire år på å opprette et lovverk for å beskytte personvern. Denne loven er i dag kjent som GDPR (General Data Protection Regulation), og trer i kraft mai 2018. GDPR er et helt tema i seg selv, men kort fortalt handler det om å gi forbrukerne makten tilbake. Bedrifter må nå ha hjemmel eller lov fra kunden til å både lagre og behandle data om dem.
Alle firma som har kunder i EU må forholde seg til dette, noe som er en spennende utfordring for bedrifter som bruker persondata. Kongressen i USA ønsker nå en lignende lov for å få kontroll på persondata og misbruk av disse. Hvorvidt dette kommer til å skje er vanskelig å si, da USA selv samler inn og behandler persondata på ulovlig vis.
En verden av muligheter
Vi lever i en kompleks verden. Heldigvis må man ikke kunne programmering for å få kontroll og innsikt i dataene sine. Det finnes verktøy som gjør dette mulig uten å måtte programmere, som f. eks. Google Data Studio som Caroline Dalland skriver om i sitt blogginnlegg.
Uavhengig av hvilket verktøy eller teknologi man bruker for å tolke dataene sine, så er det viktig å være oppmerksom på hva som finnes av muligheter. Hvis man samler sammen data, organiserer, og presenterer dem på en fornuftig måte får man praktisk talt superkrefter; bare husk å ikke misbruke dem.