
When setting up a Data Mesh focused data platform, the fundamental organization is a key question which can be difficult to approach efficiently. How should you structure your data platform to enable usability, sustainability, cooperation, decentralised autonomy, security and privacy? In this article a number of concrete suggestions and patterns will be presented. It is fairly technical, intended for data platform engineers and architects, ML engineers, Data Engineers, and full stack Data Scientists.

Urban planning or the lack of it. Photo: Office Towers and Favela, Adam Jones, Ph.D. License: CCASA 3.0
“Growth is inevitable and desirable, but destruction of community character is not. The question is not whether your part of the world is going to change. The question is how.”
Edward T. McMahon, Urban Land Institute Senior Resident Fellow for Sustainable Development
This article will propose some suggestions for structuring your data work on the data platform service Databricks, including naming and organising data products in Unity Catalog and git. Databricks is available as a meta-platform on AWS, Azure and GCP. This article is fairly technical, intended for data platform engineers and architects, ML engineers, data engineers, and full stack data scientists. Even if Databricks is the focus here, a lot of the ideas in this article apply to other data platforms as well, and should be possible to understand and adapt.
It is becoming increasingly easy to get rolling with Databricks, as with other data platform services like Snowflake, Google Dataplex and Microsoft Fabric. However, how can you avoid building a data favela, without plumbing, proper transport infrastructure and security? How can you avoid building a huge urban sprawl, clogging up infrastructure and killing spaces for shared culture and learning?
Comprehensive Land Use Plan for Manila, MPDO, City of Manila. License: CCASA 3.0. It also includes areas which are not yet developed.
Even if decentralisation is core to Democratising Data, Data Drivenness, Data Mesh, enabling AI etc, some structural regulations and guidelines are useful, the same way a pre-emptive urbanism and shared building norms are powerful tools to build functional and soul soothing cities.
Table of contents
1. Desirable Qualities of Data Work
What qualities should we plan for?
2. Environments in the Data Platform
How to organize dev, staging, test, prod on Databricks?
3. Planning for Quality: Structure plans and proposals
-
3.1 Structure plans for Decentralised Data Work
-
3.2 Unity catalog structure plan
-
3.3 Git-versioned Data Work
-
3.4 Democratise the Data Work and Hide Cloud Engineering
-
3.5 Let Unity Catalog manage cloud resources and tables
-
3.6 Getting started examples for core tasks
-
3.7 Automated data quality checks
-
3.8 Workspace distribution
-
3.9 CICD
-
3.10 Central Data Platform Enabling Team
4. Conclusion: A sustainable development plan
5.Vocabulary
Definitions and terms
1. Desirable Qualities of Data Work
Based on the growing body of experience with data platforms, we can point to some core desirable qualities of data work which should be reflected in data platform urbanism, that is, the design principles implemented in the structure plans and other aspects of the data platform engineering. Done right, these principles will prevent chaos, prescribe conventions, and educate users by the power of example.
Usability
It should be easy to use the data platform, even for less technical users. Onboarding should also be self-service and pedagogical. For an organisation to become data-driven, usability is crucial. Easy comprehension of the structure and ways of working is a part of it.
Sustainability
Even if it should be easy to use the platform, data work ought to be sustainable, both in terms of respecting the space of other data workers, and the resources of the company. However, even more important is that the data work can be maintained and understood over time. With sustainable, I here refer to technologically and organisationally sustainable, not ecologically (which is a much greater question).
Cooperation
Cooperation and knowledge sharing across teams can be enabled by following common examples and conventions for organising code, data and pipelines. In addition, low-threshold arenas for knowledge sharing must be enabled, like Slack and QA fora. Without cooperation, building a much-needed data culture is hard to achieve.
Autonomy
Each team and data worker should have a space, resources and freedom to go about solving their data needs.
Security
Responsible access management should be enabled by design. By having clarity and comprehension in the structure plan, security becomes much easier to implement and maintain.
Privacy
Solid examples of privacy-respecting data handling should be provided, at least as soon as privacy-sensitive data will be processed. Audit Logging is a great tool to capture who has queried which data, and also implement security practices.
Data Worker User Experience
The data worker should be easily able to start doing data work. It should be easy to:
-
get access to and obtain data
-
know where exploratory code and data assets will be stored, and how to name them
-
follow branch name conventions and commit code
-
share code across projects and departments
-
deploy code to automated execution (production)
-
apply data quality checks
-
perform access management
-
investigate failing pipelines
-
test run data pipelines
-
have access to production data where it is permitted, to do analysis and build ML on real data
-
if the use case proscribes it, easily handle data consumption and production in a privacy-respectful manner
2. Environments in the Data Platform
This section will explain why App Engineering and Data Engineering should treat environment separation differently.
App Engineering vs. Data engineering
App engineering normally deals with precise data.
A typical data interaction is to query the application's database for precise data to display/change/transaction data on behalf of a specific user.
E.g. Find the start dates of courses for student:
Find the start dates of courses of student with student_id=1
On the contrary, data engineering normally focuses on patterns in data.
A typical data interaction is to query different databases/data sources for all the data in some tables, also across databases, in order to study patterns.
E.g. Find the popularity of all course types across all course choices for all students across databases from many different universities, for the last 10 years.
Developing on real (production) data
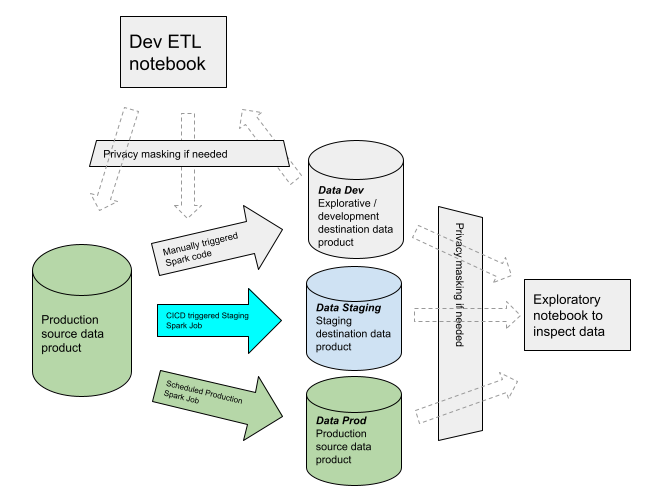
Data development and staging need access to production data, although sometimes masked.
Given the difference in the need for real data, there are also differences in the environmental separation for the cloud infrastructure when building a data platform, as opposed to an application platform.
In an application platform, it is often useful to distinguish between environments for development, testing, staging and production, and the data used in these usually have clear distinctions. Development and testing will usually use synthetic data, while staging and production use real data. It can therefore be useful to have a totally separate environment for development and testing.
In a data platform however, there is a need to have access to real data already in the development phase.
Testing app functionality vs data functionality
Given the differences in data interaction, testing app code often fulfils a different role than testing data code.
Typical app test
-
Given a student with three courses starting on August 15, 17, and 18, return a list of exactly those courses and start dates.
-
If the test fails, cancel deployment of the app.
Typical test tool: Pytest, JUnit
Typical data test
For data engineering, data quality tests are often more useful.
-
Check that the number of course categories across the databases is a minimum of 90% or a maximum of 120% of the number of categories from the previous year.
-
Check that all courses have at least one course category.
-
Courses which lack categories should be rejected or quarantined.
Typical test tools: Great Expectations, DBT, Delta Live Tables
Environment proposal
Here is a proposal for defining environments in a data platform.
Cloud environments (AWS accounts / Azure Subscriptions)
-
Infra dev: Use for cloud engineering, i.e. building the data platform itself, adding new orchestration tools. Will not be accessed by data workers, only by data platform engineers.
-
Infra prod: Used for developing data pipelines, and running these pipelines in automated production. Will be used by all data workers.
Infra Prod can contain several Databricks workspaces, or there can be one infra-Prod account per workspace. I would suggest keeping one workspace per account, to reduce blast radius on cluttering.
Data environments
-
Dev: Exploratory data work (ML, ETL, Analysis, data pipeline development).
-
Staging: staging environments are used to run a new version of a data pipeline or task, to test them, before they go into production.
-
Prod: these pipelines should run in an automated, stable and secure manner, without errors.
All of these should reside in Infra Prod.
Note that Dev needs access to real data (i.e. production data). In some cases data should be filtered/masked production data. There might be cases where completely synthetic data must be used, however this challenge must be solved specifically, to build data pipelines producing useful data even if data visibility is reduced during development. This challenge will not be solved by a simple cloud environment separation, unlike for app platforms.
3. Planning for Quality: Structure plans and proposals
.jpeg?width=2560&height=1461&name=Old_Port_and_historical_center_of_Dubrovnik%2c_Croatia%2c_a_view_from_the_south_(48613003236).jpeg)
Old Port and center of Dubrovnik, Croatia, a view from the south. Dronepicr, License: CCA 2.0
Aiming at enabling the core qualities of data work, and taking into account the specific characteristics of data platforms, concrete suggestions will now follow for organising the data platform engineering.
3.1 Structure plans for Decentralised Data Work
Data mesh has become a common concept in data platform engineering. It is a comprehensive topic, with disagreements/variations on recommended architectural patterns. These will not be covered here, but we will focus on decentralisation of ownership of data, which is a core feature that platform engineers agree upon. Each department should own the data products coming out of it. In this article we will mainly focus on the decentralisation of data work, enabling autonomy, but also cooperation and sustainability.
A data product structure plan is necessary to enable cooperation, autonomy, sustainability and Data UX across a large organisation.
Structural dimensions
A data mesh data product hierarchy could be broken down into these levels:
-
Organisation (Acme Inc)
-
Domain (Sales)
-
Project (Customer Analysis)
-
Data Product (Customer Classification)
-
Tables (customer_classification, classification_codes)
-
Data product version
This enables us to not mix up each projects' data assets and code.
This data product hierarchy must be reflected in components of the data platform:
-
Unity Catalog, schema and table naming
-
Git-repository structure
-
Workspace distribution
-
CICD environment handling (e.g. naming of development and staging pipelines)
-
Data Pipeline naming
Thus, the structure plans must cater to a number of dimensions:
-
Data product hierarchies
-
Distinct types of data work: ML, Data Engineering, Analysis. Each of these might require different file types and pipeline ops, sometimes warranting structural separation.
-
Data access management
-
Data Environment Separation (dev, staging, prod)
-
Data Development Experience (where do I put my experimental tables and code? Where do I test run my new data pipeline?)
Let's now look at a concrete structure propal to accommodate these dimensions.
3.2 Unity catalog structure plan
In the data asset hierarchy it will be enough to have the six levels of data product hierarchy, plus one level of environment separation. Unfortunately Unity Catalog only provide three levels of hierarchy: catalog, schema and table. It is a strong suggestion from Databricks to only use one metastore if data is to be shared, so four levels are not available, only three. To accommodate all levels we will need to use prefixes or postfixes.

Implementation proposal for Unity Catalog
A number of choices have been made which might be disputed, but here is the reasoning.
A Data Product needs two levels of hierarchy
Since a data product is often made up of several data assets or tables, e.g. a star schema, we need to preserve the schema level of the unity catalog for the data product. We need the tables on one level, and their grouping, i.e. the data product, on the schema level. This already consumes two of our three levels.
Area as catalog
The catalog should correspond to an area to simplify access management, which then can be granted (with Unity Catalog grant statements) on either area level or data product level. One area can contain multiple data products.
Environment prefixing
The environment prefixing at catalog level gives a crystal clear separation between environments. However, one could argue for postfixing instead, since sorting on org+domain could more relevant, so putting env as postfix is not a bad alternative.
In any case, by keeping env on the top level together with area, a clear overview of official data products can be seen by filtering on prod_ prefix. Access management during CICD and jobs runs also become clearer, and therefore more secure.
Another advantage of keeping env in catalog name, and not pulling environment into the schema name (level below), is that queries can be developed and then deployed to production without having to change the schema name.
Explicit versioning of data products
Versioning should be an explicit part of the data product name, to avoid version lookups in meta data, when building and running pipelines. It also permits producing separate versions of a data product in parallel, which might be needed by downstream consumers.
Development branch as environment

Unregulated street vendors. Railway Market, Make Klong River, WallpaperFlare. CC License.
When developing new tables, normally a data worker would call it something like testpaul2_classifications. Chaos spreads quicker than street vendors on an unregulated street.
So having and facilitating a convention for naming development tables makes everyone's life easier.
A suitable prefix could be dev[issue id][shortened title].
It could also be made an enforced practice that all data work should happen in the context of a git branch.
Staging environments
Instead of putting staging in the env name we use pr, to signal that it is a pull request running, but stg could also work. The env prefix format would be:
pr[ticket number][shortened title][short commit hash], e.g. pr745enrich1a6f396
This enables parallel execution of multiple pipelines consuming the same data product. By beginning with pr, we clearly state that it is a staging environment. It is a good idea to include the commit hash also, to avoid conflicts with parallel runs of the same branch.
Environment-agnostic code
A pyspark utility function or sql constant should be used to automatically get the catalog name, including the environment, based on the execution context. Databricks has great utility functions to deduct which run time context a notebook is running in (workspace name, cluster name and type, interactive notebook etc). Note that upstream data assets should be read from production (or masked production), while the data assets being created by the pipeline being developed should run in dev or staging before the branch is merged to main and deployed.
Streams and ML Models
Beyond tables, data assets can also be ML models or streams. They might not always fully fit into the implementation suggestions outlined here, but the higher level principles can still be applied.
3.3 Git-versioned Data Work
A git repo should be used as a workbench, instead of using an unversioned folder under "Workspace". The simplest is for each user to checkout a monorepo, which the platform team facilitates, so that all data work takes place there, with support and examples for the desired structure and ways of working, out of the box. An example of such a repo can be seen here.
In Knowit, we use, among other things, a monorepo for the internal data platform, where all the data domains' code is included, unless something else is absolutely necessary.
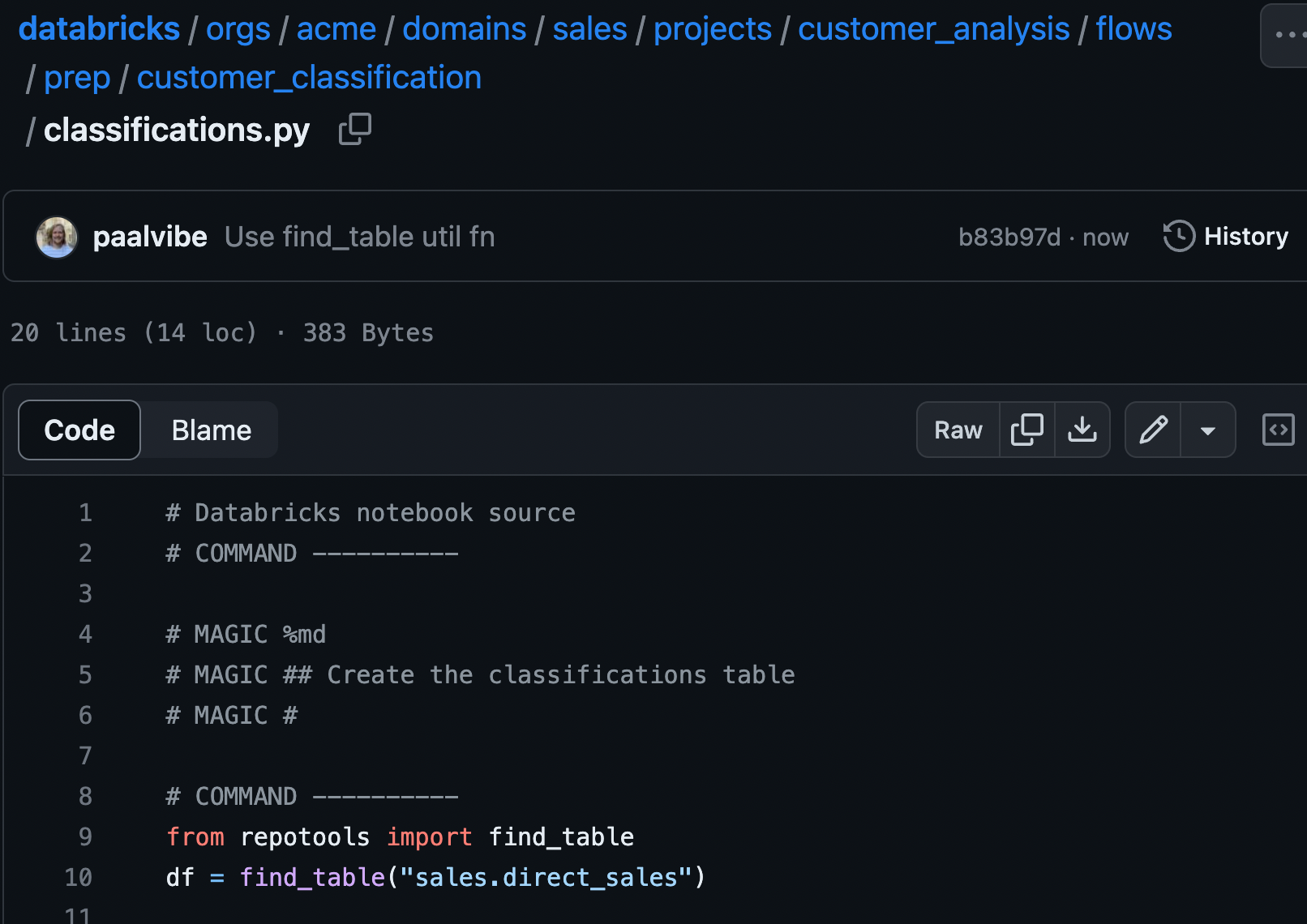
Monorepo example viewed in github
In the repo structure, projects correspond to the area level of data mesh, in this case, customer_analysis. The flows folder has separate folders for ML and prep (ETL) flows (pipelines). Shared code can either be put within the project's libs folder, domain libs folder or in the root libs folder, depending on how universal the python functionality in the module is.
More details can be found in the monorepo example. There is also code in the repo example for unit testing pyspark code, which can be done as part of a CICD pipeline, for solidifying pipelines. Note that spark just released more functionality for unit testing, which has not been incorporated in the example yet.
Using a shared repo becomes a catalyst for cooperation and knowledge sharing, and enables a very easy and direct way for people to gradually build their tools with git versioning.
It is also a great place to document data pipelines.
Documentation close to the code
The documentation for the data work should be close to the code, e.g. in README.md files inside the flows folder producing the data assets. Easy to find, easy to purge when the code dies.
Git-versioned orchestration directly in the Databricks UI
All data work, including orchestration should be possible to do directly in Databricks' UI. A good way to achieve this is to use yaml files to define Databricks Jobs, for orchestration, and let CICD automatically deploy this as Databricks Jobs using Databricks' good APIs, on git events. E.g. you can trigger a test run when a new branch commit happens, staging run on a new commit to a Pull Request, and production deploy on merge to master. Advanced users are free to pull the code down on their own laptops if they want more advanced editor functionality, e.g. for refactoring, and use Databricks Connect to interact with clusters and data.
Your Repos folder is your Virtual Laptop
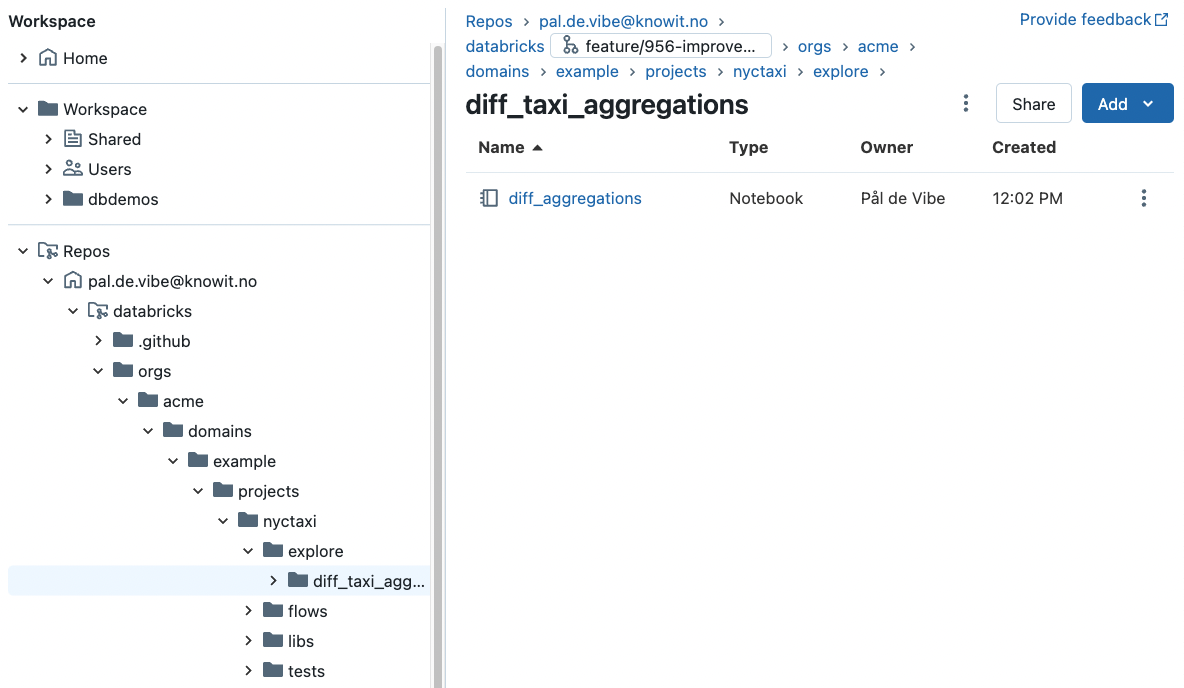
Your Repos folder is your Virtual Laptop and Workbench
When beginning with Databricks it is often tempting to use the Users/username folder or Shared folder under Workspace as a workbench for data work. Instead you should checkout a monorepo, and begin working within a project, under the explore folder (e.g. projects/nyctaxi/explore/diff_taxi_aggregations). This way, the code being created already have a hierarchical position corresponding to their organisational position. The naming of the data asset naming (schema and table name) should follow a corresponding naming pattern as the code. Everything becomes much clearer. Fewer choices need to be made, and less chaos is created. It also enables git version controlling your experiments, and sharing them with others.
Your personal Repos folder is a lot like a virtual laptop.
-
In your personal repo-folder you checkout repos
-
Only you work in it (but you can share access to it)
-
Collaboration happens through branches, like you would do with code on your physical laptop
-
Share code with your physical laptop (e.g. for refactoring code) or other team members
In general it is very similar to checking out a repo and working on it on your physical laptop.
The same repo can be checked out multiple times.
The repo-integration (git UI) in Databricks is an easy way to use git for non-developers.
Pull Requests as proposals to put code into production
Pull requests are great for representing a proposed addition or change to production pipelines. The code diff is easy to study, comments can be made, CICD-validations implemented, four-eyes approval regimes enforced. My experience is that non-developers understand Pull Requests fairly easily.
3.4 Democratise the Data Work and Hide Cloud Engineering
To become a data-driven organisation it is key to empower data workers on many levels/roles to do their job, as much as possible on their own, in an efficient (but responsible) way.
Ways of working must be cultivated to make it easy for less technical workers to use the data platform. The git repo described above is a fitting tool to achieve this. But here are a couple of additional proposals to enable.
Isolate data work from cloud engineering

Don't drag your data workers down into the cloud engineering. Photo: Unknown source
To simplify data work, especially for non-developers, the data platform should isolate the data workers from direct cloud engineering. They should not have to relate to the entire apparatus of cloud engineering, e.g. the entire terraform setup and terraform state. Therefore, all data work should be possible to do right in the Databricks' UI. More technical users can still download the Databricks repo onto their own machine, and work via Databricks Connect and Databricks' APIs.
Leverage technologies empowering less technical Data Workers
Tools such as Notebooks, Delta Live Tables (DLT), Databricks SQL Dashboards and DBT empower less technically experienced employees. DBT is a very good tool, but it can also lead to splitting the user interface into several platforms (both Databricks and DBT Cloud), and it is therefore often best not to start with DBT. DLT is partly inspired by DBT and provide similar data quality checks, although DBT's opinionated file structure by default enables cleaner implementations of pipelines.
3.5 Let Unity Catalog manage cloud resources and tables
Unity Catalog is the new brain of Databricks, and is designed partly to simplify access control to cloud resources, which can be a complex task. In addition, there are a number of other efficiency-enhancing functions that are gradually being added to the Unity Catalog, e.g. column-based lineage.
It is complex to keep track of cloud resources only with the help of IAM roles, and this also means that data work is mixed with cloud engineering, for example manage access to a data.
In general, one should avoid trying to build functions which Databricks itself solves or is about to solve, e.g. support for DBT and Airflow orchestration, which are now supported in Databricks Jobs. Another example is Databricks cost dashboards to monitor what data work spending.
Please note that the Unity Catalog, as of today, does not necessarily solve all the needs that one wants to be solved by a data catalog. An easy way to get started with a data product catalog is to simply use one or more delta lake tables as a data product catalog. This can provide fast speed, easy automation, large learning space and integration opportunities. Eventually, you will get a clearer idea of what extra catalog functionality is needed.
3.6 Getting started examples for core tasks
In general, providing example code and pipelines for core tasks and use cases, including good naming practices, is extremely useful to avoid unnecessary diversity in ways of working, naming and coding practices. Implementing enforced Black linting is also very useful. In the CICD linting checks can be added.
3.7 Automated data quality checks
The shared repo should have some examples of data quality jobs and pipelines, with Delta Live Tables or other frameworks like Great Expectations. Automated data quality is essential for good data work, and good examples, working out of the box, will help to get automated data quality checks into use. DBDemos can be a place to start looking for examples to incorporate.
3.8 Workspace distribution
How many domains should share a single database workspace? My general recommendation is to limit each domain to a single workspace. This way the blast radius for data access is naturally limited, and the amount of artefacts (notebooks, folders, models, repos, jobs) created in a workspace becomes more manageable, without losing overview.
3.9 CICD
Here are some suggestions for managing automatic deployment to production with CICD.
-
A new PR run is created per Pull Request, per commit hash, with a unique catalog to write the data.
-
All data work code which is merged to the main branch is automatically deployed to production.
-
Production takes place on job clusters, but in the same Workspace as development, but with tighter access control of the data.
-
Self-service orchestration. Pipelines/jobs/flows are defined in e.g. yaml in the repo, and is deployed automatically with CICD.
-
PR pipelines run on job clusters on each new commit to a PR. This way, the yaml definitions of jobs can be tested iteratively before they are put into production.
-
Since you can end up pushing a commit before a PR test is finished, it is best to use the commit hash as part of the schema name.
-
Automatic validations should be implemented in CICD: incoming and outgoing table schema and data quality verifications, black linting, automatic privacy alerts etc. Non-compliant code can be blocked from deployment.
-
DataOps and MLOps might have different needs, but CICD and PRs is a great place to handle a lot of the Ops.
3.10 Central Data Platform Enabling Team
As suggested by Data Mesh theory, the organisation must commit to staffing a central data platform enabling team, to cultivate the tools, structures and ways of working to democratise and the data work. Internal training and knowledge sharing must also be prioritised.
4. Conclusion: A sustainable development plan
A number of proposals for structuring your Data Work has been presented. Much like a city, the consequences of bad or missing planning will manifest over time, and become increasingly hard to change. On the flip side, by creating liveable and even beautiful cities, we enable people and communities to thrive and flourish, and the same goes for data platforms. Few challenges are more important for a company than this, as we enter the Age of AI.
Even the ancients apparently agree with this focus, and the crucial impact it has on culture and people:
By far the greatest and most admirable form of wisdom is that needed to plan and beautify cities and human communities. - Socrates

The Course of Empire: The Consummation of Empire (1836) by Thomas Cole. License: Public Domain.
If you want to discuss how to apply these principles in your organization, don't hesitate in reaching out to me on email or LinkedIn.
5. Vocabulary
For clarity, here are some definitions of relevant terms:
-
Data platform: A collection of tools and services, preferably in the public cloud, that make it easy to transform datasets and build data products.
-
Data product: One or more data assets which it makes sense to deliver and access-manage jointly, e.g. the tables in a star model, a Kafka stream, or a machine learning model.
-
Data asset: A table, machine learning model, Kafka stream, dashboard or similar.
-
Data work: All work with data assets on a data platform, e.g. data engineering/ETL, Machine learning, MLOps, orchestration of data pipelines, SQL analysis, dashboard building, dashboard analysis.
-
Data worker: Those who use the data platform, e.g. data engineers, analysts and data scientists.
-
Data mesh: A methodology for structuring data work, systems and data products in an organization, with decentralised data product ownership.
-
Data area: A category for grouping related data products, for example the data products studying private customer sales.
-
Data domain: A team, a department or other part of the organisation that produces data products which the domain will take ownership of.
-
Data ownership: To take responsibility for delivery, versioning, design and documentation of a data product.
-
Cloud engineering: Building and maintaining cloud infrastructure.
-
Application development: Development of applications with user interfaces which are not focused on data work.
-
Application platform: A collection of tools and services, preferably in the public cloud, that make it easier to build applications.
-
Data development: Data work on a data platform to produce data products or insights.
-
Synthetic data: Fake data created to represent real data.
-
Real/production data: Real data used in production systems.
-
Ways of working: An opinionated way of going about a common data work task.
-
Data Pipeline: A sequence of data assets produced together with dependencies between them.
-
Structure plan: A plan prescribing where different teams and data activities should take place, within git-repositories and the lakehouse structure (Unity Catalog). Includes naming conventions and examples.


