
What is it that makes processing of industrial IoT data streams so difficult to master?
There are multiple reasons, but most of them boil down to the fact that a large amount of data is received, in continuous streams that never end. Quite possibly, you’ll need to identify trends within those streams. Just observing the latest sensor measurements as they stream by won’t be sufficient anymore. Then you need a really fast short term buffer. Preferably one where you can store your own calculations for reuse as if they were ordinary sensor measurements. Let’s call this warm storage.
Data sources and data rates

There’s never one single machine to monitor. Always a number of them. Multiple buildings, one or more factories, a fleet of ships, all of an operator’s subsea oil pipelines. That kind of scale. Industrial IoT is never implemented just for fun. There needs to be real, reasonably short term, economic value involved. Alternatively it needs to be about fulfilling new environmental requirements.
One of the storage solutions I’ve been working on is currently receiving more than 14.000 sensor measurements per hour per smart building. 340.000 values per day. Each smart building is equipped with more than 5000 sensors. That storage mechanism is almost idling now, ready for scale out, enabling thousands of smart buildings to be connected in the near future.
Processing on edge devices
IoT data may need to be buffered for multiple weeks, if your sensors and equipment are at sea. IoT data streams don’t have to be transmitted in real time to provide value. Though, sometimes you’ll want to perform at least parts of the processing on site. For example optimization of fuel consumption for tankers and tug boats, or detection of anomalies or maintenance prediction for subsea oil pumps.
It’s perfectly possible to run trained machine learning algorithms on quite primitive equipment, like relatives of Raspberry PI, or a small rugged PC. Maybe directly on your IoT gateway, that in some cases can be as powerful as any server blade. You also won’t need a lot of machines to be able to deploy a reasonably redundant Kubernetes cluster.

Dashboards and reports
Most customers of industrial IoT require more than just a callable machine learning algorithm that detects some anomaly. They often require dashboards for like how production does in real time, with fancy graphs, multiple dimensions, color coded performance and downtime.
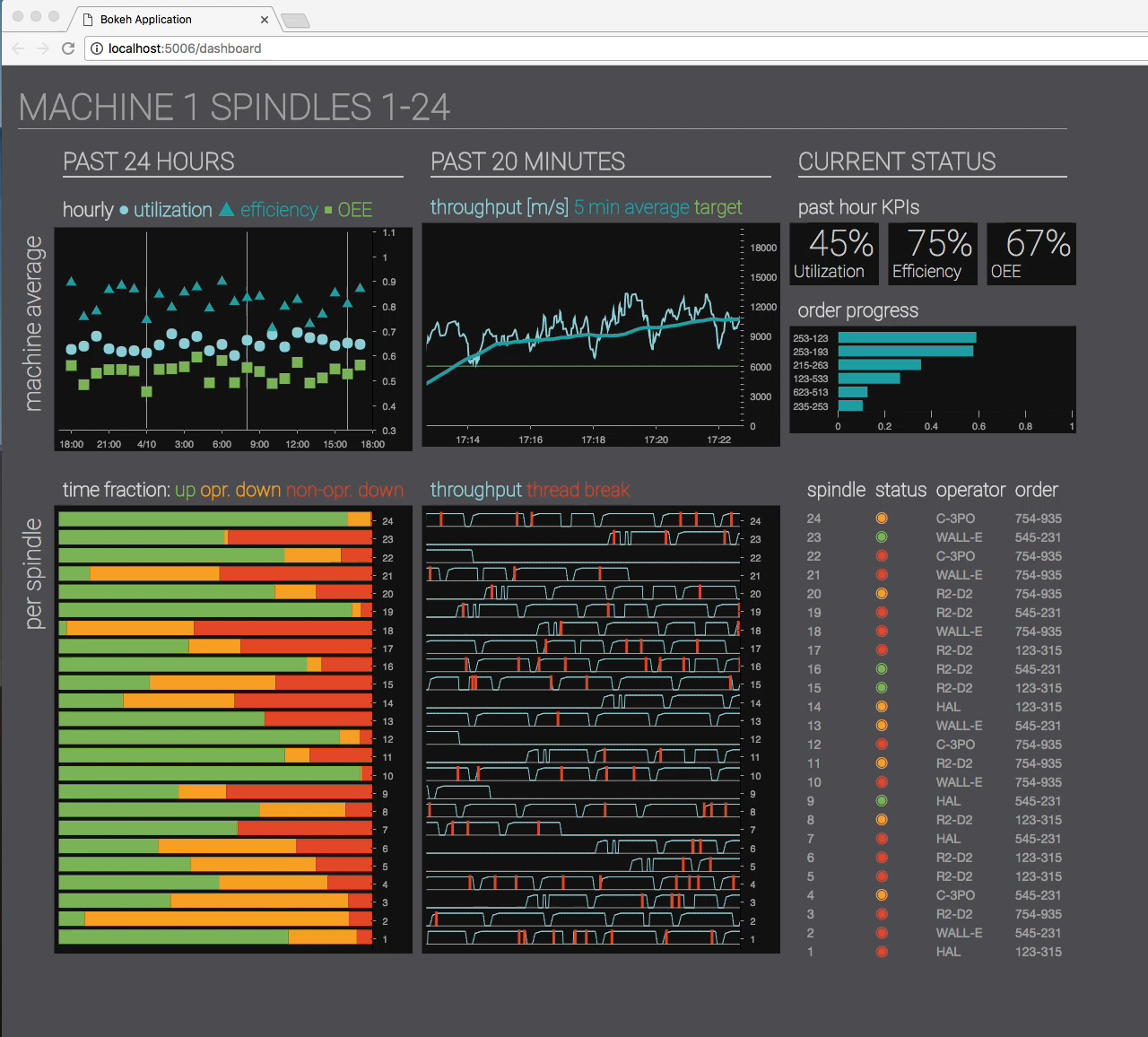
These dashboards may have low practical utility beyond showing them off at board meetings, or talking about them to people you want to impress. But they can on the other hand be extremely hard to implement. Particularly when your customer also wants parameterizable reports that can compare current and historic periods of time.
Warm storage
The key to create fast updating charts and reports, is to store the underlying data on a format that can easily be combined into the desired result, with a resolution that doesn’t require too much work per recalculation.
Warm storage is often used used by Data Science applications, and algorithms that call machine learning models, in order to quickly retrieve sufficient sensor values and state changes from streaming data. Warm Storage data may typically be used to detect anomalies, predict maintenance, generate warnings, or calculate Key Performance Indicators, that add insight and value to streaming data for customers.
Those KPIs are often aggregated to minute, ten minute, hour or day averages, and stored back into warm storage, with a longer retention period, to facilitate reuse by further calculations, dashboards or reports.
A good Warm Storage needs flexible low latency querying and filtering for multiple time series simultaneously. It must be able to relate to hierarchical asset properties for flexible matching and filtering. And it needs query support for seamlessly mixing calculated data, sensor data and state changes.
The first rule of warm storage is: Don’t store data you won’t need. Excess data affects the performance of retrieving the data you want, costs more money, and brings you closer to a need for scaling out.
A good Warm Storage should have a Python wrapper, to make it easier to use from Data Science projects. If you’re using Warm Storage in a resource restricted environment, like on an edge device, the API should behave the same as in a cloud environment.
Query driven design
Storage is cheap. Store IoT data the way you want to read it. Feel free to store multiple copies in alternate ways. That’s called query driven design. Don’t be afraid to utilize multiple storage services for different purposes. Joins and transactions are as good as irrelevant for IoT data streams. They don’t change after they’ve been sent.
Micro batching
Database systems like Cassandra support batching of commands on an API and protocol level, and can execute batches asynchronously on multiple nodes. That’s particularly effective when the entire batch uses the same partition key. But batching can be supported even using SQL, when you know the syntax. Utilize this to write multiple values using the same command, so that the number of network roundtrips is reduced. I’ve seen both hundredfold and thousandfold speed increases purely as a consequence of micro batching.
Warm storage data flow
This is an example of a good architecture for processing industrial IoT data streams.
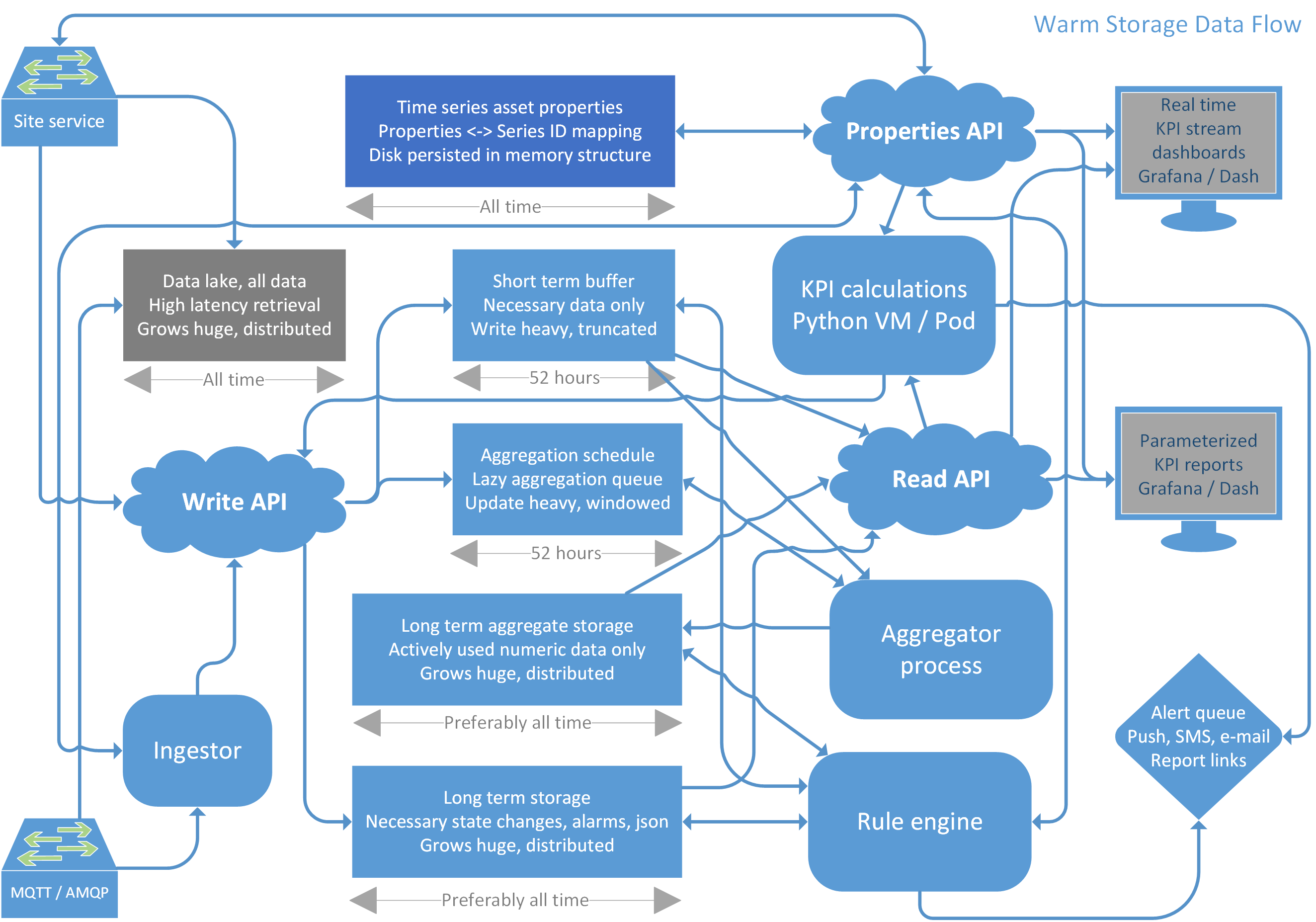
There’s a low latency time series properties store that handles searching and mapping between hierarchical asset properties and globally unique time series IDs. A disk persisted in memory data structure would be optimal for this.
You have a low latency short term buffer that supports micro batch insertions and fast retrieval of multiple time series from IDs and time range. The short term buffer uses retention policies or truncations to expire data older than a couple of days. InfluxDB or TimescaleDB are particularly good for this, and can be scaled using sharding for different customers or equipment if necessary.
There’s a low latency aggregation schedule queue, that lazily postpones aggregations until a short randomized period after each aggregation interval has finished, in order to reduce the total aggregation processing cost.
You have a long term storage for data that shouldn’t be aggregated, for example state changes, alarms or structured json documents. Distributed cloud databases are ideal for this. I particularly like Cassandra and ScyllaDB, which compress data extremely well. Consider never retiring data written to Cassandra, because of the cost of recompression while reclaiming storage space. InfluxDB or TimescaleDB are good alternatives for Edge computing.
The long term aggregate storage is similar to long term storage, but only holds count, sum, sum of squares, min and max of numeric time series. The average, standard deviation and variance can easily be inferred from these, for all multiples of the base aggregate interval. Sensible interval durations must be selected with care, as they represent a compromise between precision and storage size, which is basically what decides how fast you’ll be able to retrieve or process a result, or display a relevant graph.
Remember that the warm storage solution is meant for low latency presentation ready data. You should utilize an additional and separate data lake if you want to store every tiny detail forever, for training machine learning algorithms, traceability, playback or whatever.
API methods
The API methods listed here are not required for all warm storage instances. You won’t need Data Scientist oriented retrieval methods, if your storage needs all revolve around aggregation, and displaying graphs of historical data. So consider this a mixed wishlist of API methods that might go well with varying types of warm storage solutions.
Write API
- Insert/Update micro batch
- Set/Delete lookup values
- Truncate short term buffer
- Inquire health status
Properties API
- Find GUIDs from properties
- Find properties from GUIDs
- Register properties
- Modify properties
Read API
- Get short term buffer values for GUIDs / last seen
- Head/Tail of short term buffer
- Align buffer GUIDs values to interval / forward fill
- Aggregate functions and percentiles for buffer GUIDs
- Histogram/Buckets for buffer GUIDs
- Get long term storage values for GUIDs / last seen
- Durations between long term storage GUIDs values
- Get aggregates for GUIDs
- Combine aggregates for GUIDs
- Tumbling/Hopping combined aggregate windows
- Graph data retrieval helpers
- Get lookup values (from key value store)
- Authentication helper
- Token renewal helper
- Should have a Python wrapper library
Security
All REST API methods must be invoked using https. You’ll need to provide certificates for both the database servers and the API implementations. You authenticate first, to receive time limited access tokens that provide a set of basic permissions. Https keep alive achieves persistent connections, and thus reduce the effort spent performing cryptographic handshakes.
It is advantageous to choose managed storage services, whenever they’re available. That’s because someone else takes responsibility for setting the service up with a sensible initial configuration, upgrading it with security patches, providing redundancy and resilience against failure, scaling the service without losing data, providing reliable backup options, and other tedious stuff that could easily go wrong.
Aggregation and KPIs
The aggregator process takes its inputs from the aggregation schedule, reads raw data from the short term buffer, and writes aggregates to the aggregate storage, over and over.
The rule engine is similar, but can perform much more complex calculations. the rules are defined using a predefined data structure, typically utilizing JSON, consisting of five main sections for: common time intervals, inputs, mathematical expressions, outputs and alert recipients.
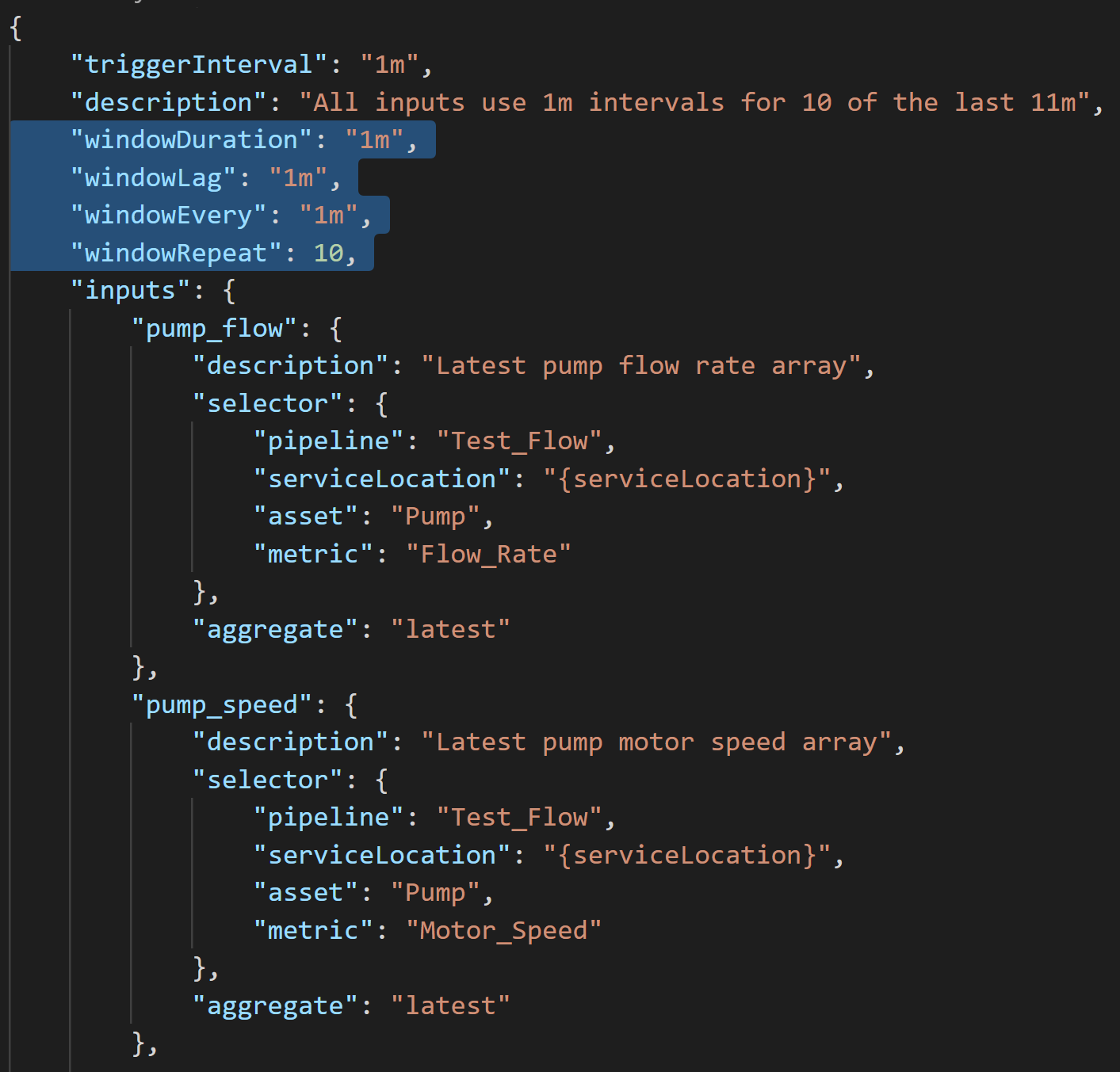
Each input can have individual aggregation window parameters, and a selector which specifies filters for a number of named properties in the property store. The selectors can contain named wildcards, which are used to connect different inputs and outputs that belong together.
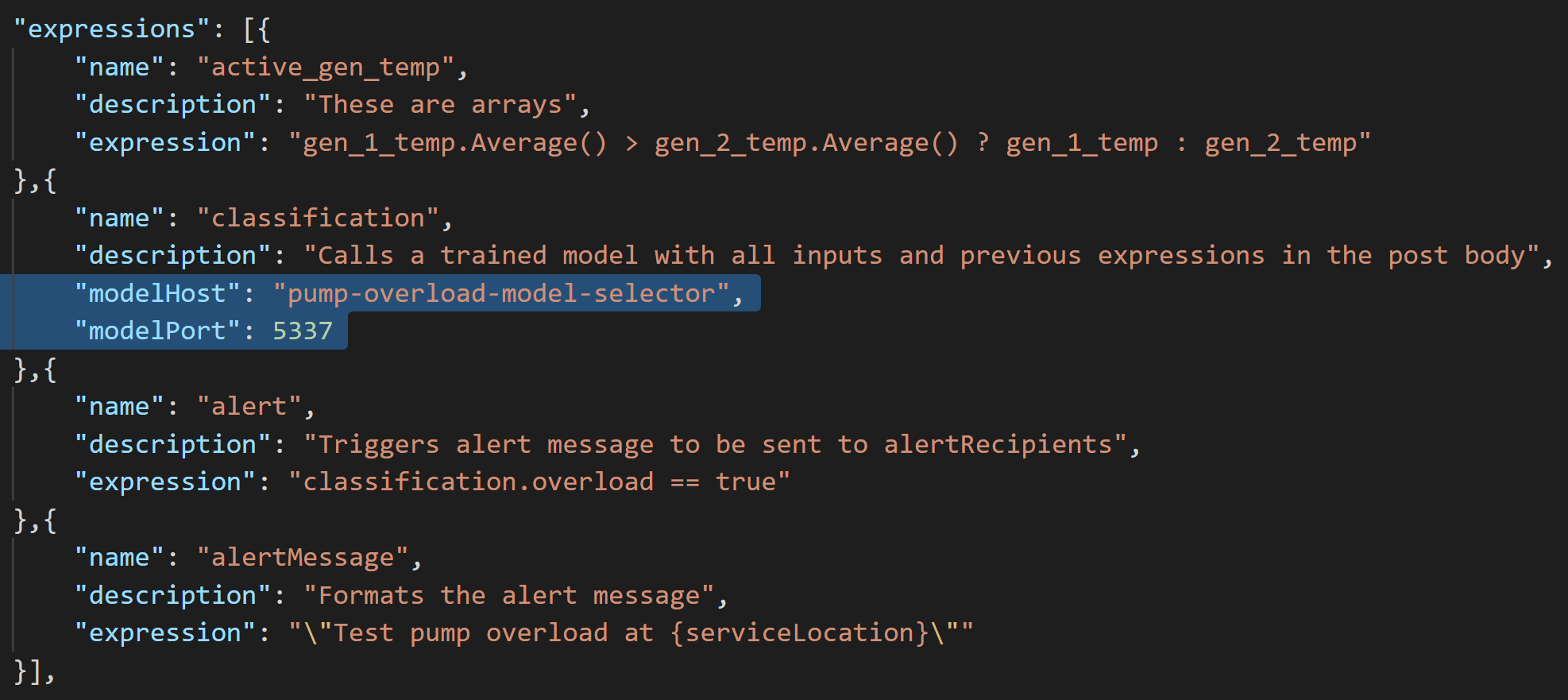
The mathematical expressions utilize an expression parser, and can by name refer to the time the rule is specified to run, each individual input, and already calculated expressions. The number of times each expression is calculated is defined by the input selector, including wildcards. Expressions may call machine learning algorithms utilizing https.
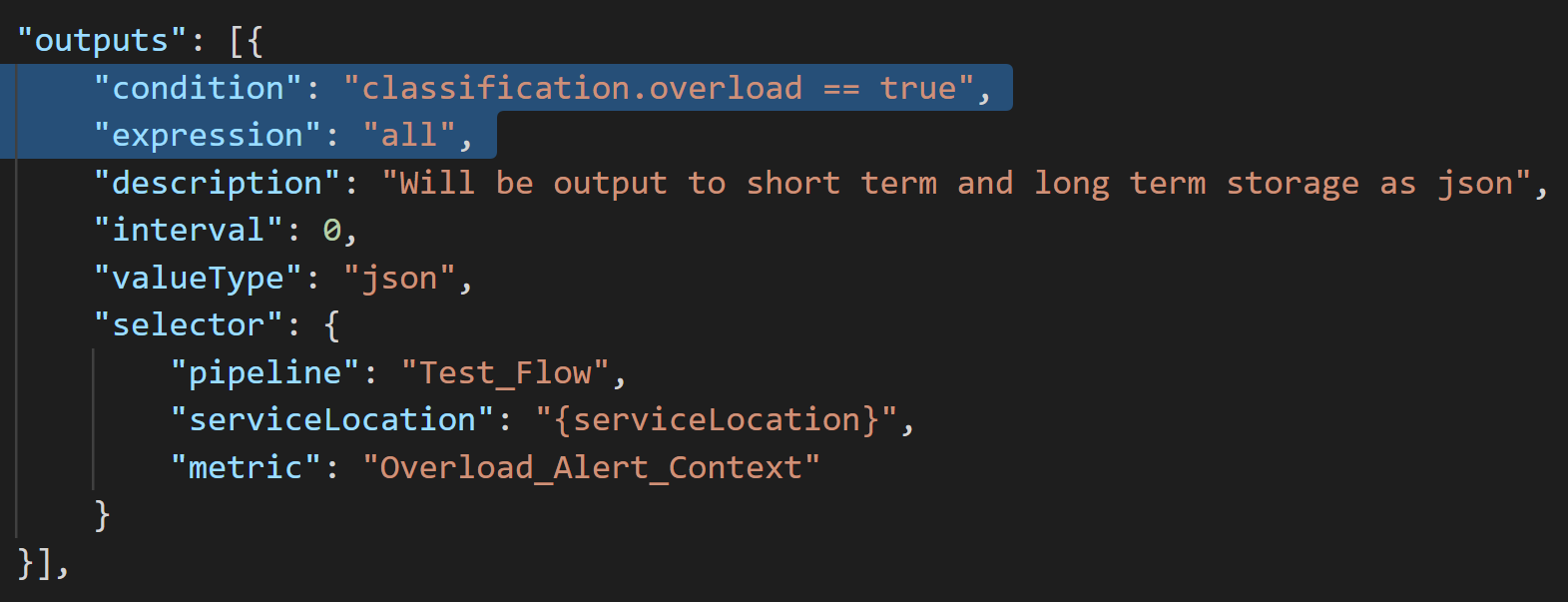
Each output can store a single named expression using a selector, which can utilize the same named wildcards as the input selectors.
Rule engines are capable of performing complex tasks quite effortlessly, provided you are careful about the performance aspects of what you ask for. Using a rule engine like this, sort of becomes the script kiddie variant of data science for streaming, and can be a good alternative to writing a dedicated Python algorithm for performing calculations.
More information
This link will take you to a long article I’ve written, which goes into much more technical detail about how to implement all of this, with lots of good advice: http://bit.ly/2W5ok8t
Or you could watch my video presentation:
I’ve just completed a very rewarding streaming IoT storage solution for PowerTech Engineering, and would be available for relevant projects on very short notice through Knowit Objectnet in Oslo, Norway.

