
Dette innlegget er skrevet av Christian Nyvoll, Lars Syversen, Arvin Khodabandeh og Tormod Flesjø.
I høst var vi flere kolleger som dro på Stackconf konferansen i Berlin med fokus på Open Source teknologier for continuous integration, containere, hybrid- og sky-teknologier. Internasjonale eksperter presenterte sine ideer for å bygge bro mellom utvikling, testing og drift. Vi fikk være med på forelesninger om infrastruktur og DevOps-livssyklusen, inkludert bygging, CI/CD, kjøring og overvåking. Vi lærte også mer om innovative teknologier og fremtidsrettet design av store infrastrukturer. Dette innlegget presenterer de presentasjonene vi ønsker å trekke frem fra konferansen, samt en beskrivelse av hvordan vi hadde det i Berlin.
Chaos Engineering
Foredrag av: Sayan Mondal
(tekst: Christian Nyvoll)
Bringing Order to Chaos: Make Your Systems More Resilient with Chaos Engineering
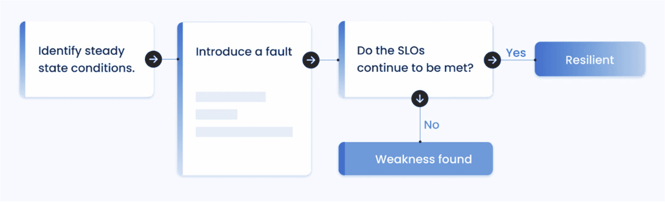
De fleste er kanskje nå vant til at det finnes etablerte rutiner for incident management, altså hva som skal gjøres av hvem, når og hvordan, i det noe går galt i produksjonsmiljøet. Dette innebærer som regel at man har et “post-mortem” møte i etterkant for å kartlegge hva som gikk galt, og hvordan man kan unngå lignende feil og situasjoner i fremtiden. På den måten bygger man seg opp og blir stadig mer robust, og får forhåpentligvis i hvert fall ikke samme feil igjen i fremtiden. Men hva om man kunne forberedt seg på forhånd, slik at en feil ikke en gang hadde måttet bli håndtert av incident management, eller unødvendige post-mortem møter? Det er selvfølgelig umulig å forberede seg på alle eventualiteter, men Chaos Engineering kan være en løsning for å komme flere produksjonsfeil i forkjøpet.
Hvis du er som meg og liker system, ryddige prosesser og kontroll i sakene dine, høres det kanskje skummelt ut med ordet “Chaos” i Chaos Engineering. Slapp av! Det er heldigvis snakk om metodisk, planlagt og kontrollert “Chaos” man skal utøve når det er snakk om Chaos Engineering. Dette for å få best mulig resultat ut av øvelsene, og selvfølgelig ikke ha noe utilsiktet “Chaos” igjen i kjøremiljøene etter at øvelsen er gjennomført. I dagens utviklingsmiljøer handler det i stor grad om å øke tempoet og deploye oftere, da er det nesten uunngåelig at det oppstår uventede feil, da det blir veldig vanskelig å holde oversikt over absolutt alle systemer og hvordan de påvirker hverandre, i en smidig og voksende digital organisasjon. Det er her Chaos Engineering kommer inn.
Illustrasjon: Sayan Mondal
Det er mange som allerede har benyttet seg og fått stor verdi av Chaos Engineering, blant annet har Netflix gjort det siden 2011 og lagt ut sitt system for bruk av andre under navnet Chaos Monkey. For å få mest mulig ut av Chaos Engineering må det være ekstensivt med metrikker på plass for tjenestene dine, og det anbefales sterkt at man har SLO og SLI definert, samt satt opp for automatisk innsamling av data for disse (Se forøvrig et annet foredrag fra samme konferanse om SLO og SLI hvis du ikke er kjent med dette; Measuring Reliability in Production av Thomas Voß i Google). Med denne dataen på plass ønsker man å kontrollert innføre “Chaos” for en begrenset periode i systemene sine. Underveis og etterpå vil man følge med på systemet, metrikkene, SLO og SLI nivåene for å evaulere på hvilken måte tjenestene håndterte kaoset. Dersom tjenestene ble for ustabile eller utilgjengelige, gjerne målt ved at SLO og SLI kom under en definert terskel, lager man en plan for å forhindre dette ved en gjentakelse av samme “Chaos”-test. Slik bygger man en robust tjeneste, som vil kunne motstå og håndtere raske endringer, og uventede feil.
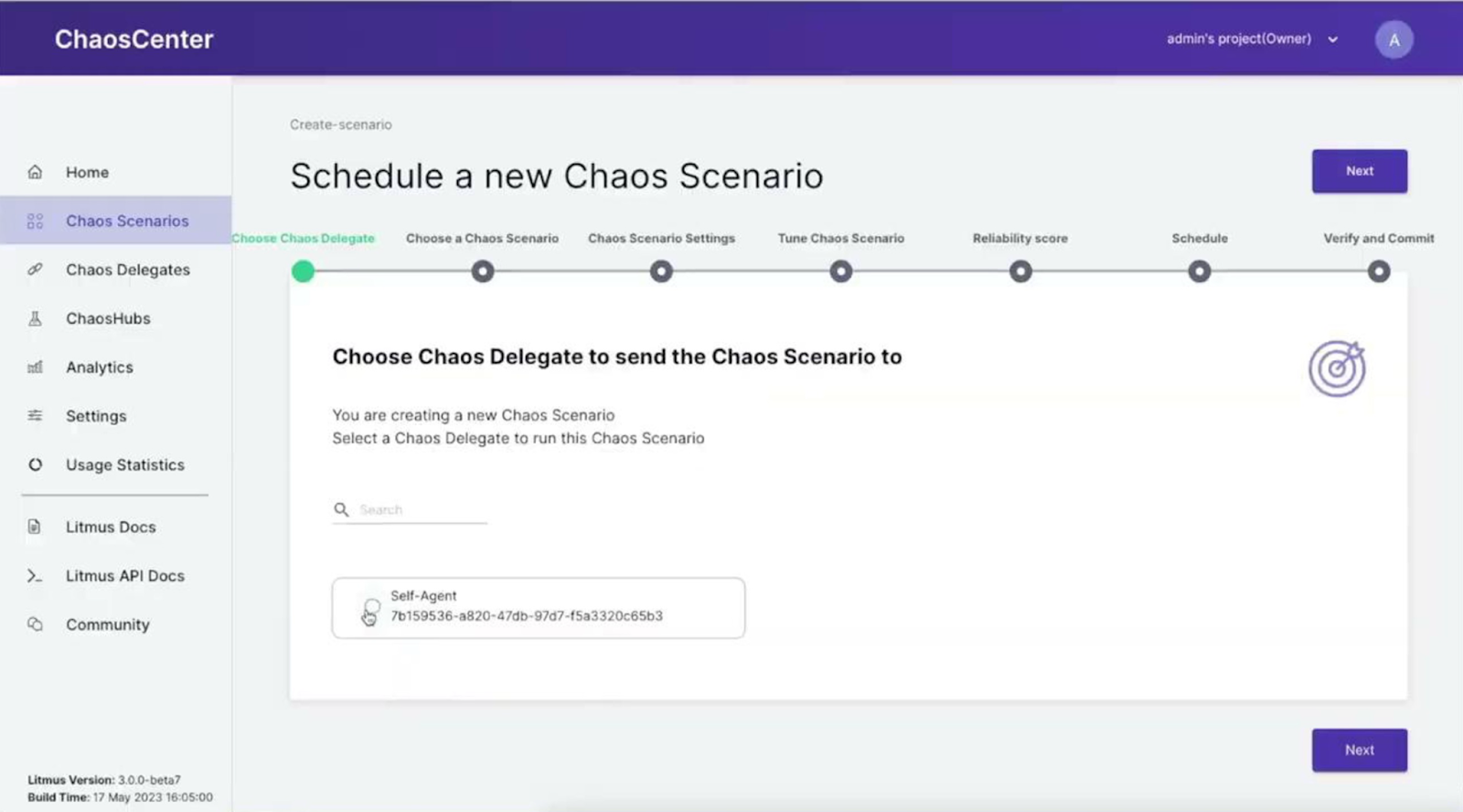
Chaos Engineering er nok fortsatt litt i early-adopters stage, men etterhvert som verktøyene blir bedre, kommer nok flere til å ta dette i bruk. Sayan Mondal viste i sin presentasjon på Stackconf frem en enkel demo av en open source plattform for Chaos Engineering kalt LitmusChaos. I demoen gikk han gjennom hvordan han enkelt brukte GUIet for å sette opp “Chaos Scenarioer”, i dette enkle demo-tilfellet at én pod (kjørende instans av en tjeneste i et cluster med flere tjenester som er avhengige av hverandre) skulle bli drept (force shutdown). Det vil simulere en veldig forenklet, men reell mulighet for noe som kan skje i et produksjonsmiljø. Da får man testet hva som skjer med resten av systemene, og hvordan det påvirker brukeropplevelsen ute hos sluttbrukeren av tjenestene dine. Han viser frem hvordan man kan sette opp at “Chaos”-et skal kjøre en viss periode, og så revertere tilbake til staten slik alt var før Chaos-testingen begynte. Ved å bruke metrikker i verktøy som Grafana kan man se hvordan tjenesten blir utilgjengelig og påvirker grafene, samt at man ved et besøk til demo-applikasjonen kan se at tjenestene som er avhengige av akkurat denne “podden” ikke fungerer som de skal.
Tilgjengelighet
Foredrag av: Daniel Yuschick
(tekst: Tormod Flesjø)
Tilgjengelighet: Tre Nøkler til Naturlig Tilnærming
Viktigheten av tilgjengelighet er ofte forstått fra et bredt perspektiv. De fleste vil si at det er viktig å lage et produkt som kan brukes av en bred gruppe mennesker med ulike behov og evner. Imidlertid er det ofte der diskusjonen slutter. Å bygge et tilgjengelig produkt krevet engasjement fra alle roller i hvert trinn av prosessen. Tid, prioriteringer og opplæring, for alle involverte kan fort være hindre.
Det er så mye nyanser og teknisk dybde når det gjelder å lære om tilgjengelighet. Det er lett å føle seg tapt i detaljene. I stedet vil denne artikkelen se på skogen som helhet og demonstrere en viktig nøkkel i tilgjengelighets-faget, nemlig POUR.
POUR Prinsippene for tilgjengelighet
Det kan høres for enkelt ut, men vi kan bryte ned tilgjengelighet i fire kjerneprinsipper - Perceivable, Operabel, Understandable og Robust. Disse prinsippene, kjent som POUR, er det perfekte utgangspunktet for å lære hvordan man skal nærme seg tilgjengelighet.
Perceivable / Oppfattbart
Hva betyr det at innhold skal være Perceivable?
La oss si at du opplever denne artikkelen ved å lese den. Det betyr at innholdet er oppfattbart for personer som kan se. Kanskje du lytter til det. Det betyr at innholdet er oppfattbart for personer som engasjerer seg med innholdet auditivt.
Jo mer oppfattbart innholdet ditt er, desto flere måter kan folk engasjere seg med det på.
Vanlige eksempler på perceivable innhold inkluderer:
-
Bilder med beskrivende alternativ tekst
-
Videoer med undertekster og/eller teksting
-
Indikasjon av tilstand med mer enn bare farger
Et flott eksempel på oppfattbart innhold i virkeligheten er et fotgjengerfelt. Når det ikke er trygt å krysse veien, vises en rød figur og en sakte, gjentakende lyd. Når trafikklyset endres og folk kan krysse trygt, endres figuren til grønn og lyden øker i hastighet. Fotgjengerfeltet kommuniserer med forståelige ikoner, farger og lyd for å skape en omfattende og sikker opplevelse.
Operabel
Operabelt innhold avgjør om en person kan bruke et produkt eller navigere på en nettside.
Det er vanlig for personen som utvikler et produkt å lage et som fungerer for seg selv. Hvis personen bruker en mus og klikker rundt på nettsiden, er det ofte den første, og noen ganger eneste, opplevelsen de utvikler. Imidlertid går måtene å betjene en nettside langt utover en vanlig mus og tastatur.
Noen viktige krav for operabelt innhold er:
-
All funksjonalitet tilgjengelig med mus må også være tilgjengelig med tastatur
-
Synlig og konsistent tastaturfokus for alle interaktive elementer
-
Sider har tydelige titler og beskrivende, sekvensielle overskrifter
Understandable / Forståelig
Hva nytter det å lage innhold hvis de som konsumerer det ikke kan forstå det?
Forståelig innhold er mer enn å definere forkortelser og begreper. Et produkt må være konsistent og empatisk både i design og innhold.
Måter å skape en forståelig opplevelse inkluderer:
-
Definere språk for å tillate hjelpemidler å tolke riktig
-
Navigasjoner som gjentas på tvers av sider er på samme sted
-
Feilmeldinger er beskrivende og, når det er mulig, handlingsrettede
Robust
På en måte er mange av oss allerede kjent med å lage robust innhold.
Hvis du noensinne har måttet bruke en kompilator som Babel for å transpilere Javascript for bedre støtte, har du skapt mer robust innhold. Nå er JavaScript bare en del av frontend, og den samme brede, pålitelige tilnærmingen bør brukes på å skrive semantisk HTML.
Måter å skape robust merking inkluderer:
-
Validering av rendret HTML for å sikre at enheter kan tolke det pålitelig
-
Bruk av merking for å tildele navn og roller til ikke-naturlige elementer
POUR-prinsippene for tilgjengelighet legger en bred, om enn litt abstrakt, grunnlag. Likevel kan det fortsatt føles som mye å vurdere når man står overfor veikart med andre prioriteringer. Denne mengden informasjon og hensyn kan være nok til å avvise noen.
Selv små forbedringer kan ha stor innvirkning på tilgjengeligheten til et produkt. På samme måte som programvareutvikling har beveget seg bort fra en vanntett tilnærming, kan vi se på tilgjengelighet med den samme inkrementelle tankegangen.
Likevel kan det noen ganger være enklere å lære mer om noe du allerede kjenner enn å lære noe nytt
Edge computing
Foredrag av: Austin Gil
(tekst: Arvin Khodabandeh)

Foto: Christian Nyvoll
Austin Gil holdt et foredrag for å forklare idéen bak “Edge Computing”. For å forenkle prinsippene bak dette brukte han strikkeluer for hunder som analogi, og at arbeidet med å generere HTML kan sammenlignes med arbeidet å strikke en lue til hunden sin. Han sammenlignet fire forskjellige teknikker:
Server-Side Rendering (SSR) kan sammenlignes med en bygning (serveren) hvor det lages luer til hunder. Kunder kan komme inn for å bestille en lue til hunden sin, og også komme med ønsker for spesialtilpasninger (tilsvarende dynamisk generert HTML).
Noen av ulempene med SSR:
-
Eieren må betale for bygningen uansett hvor mange luer som produseres
-
Hvis det er veldig mange kunder på en gang får ikke alle plass (høy trafikk)
-
Skalering opp og ned kan være kostbart og tidkrevende
-
Kunder som bor langt unna bruker lang tid på å få luen sin (høy latency)
Client-Side Rendering (CSR) kan sammenlignes med et “gjør-det-selv”-kit. Her får man utlevert garn, strikkepinner og en oppskrift, men man må selv strikke luen. Dette kan spare leverandøren for tid og arbeid.
Blant ulempene:
-
Hvor lang det tar før man får luen avhenger av hvor god man er til å strikke (hvor rask maskinvare man har)
-
Man mottar også ting man trenger for å lage luen, som strikkepinner og oppskrift (sammenlignes med JavaScript, mer data må overføres)

Static-Site-Generators (SSG) kan tenkes å være som en butikk som har masseproduserte luer. Det krever lite for å ha de tilgjengelig (billig hosting), og disse kan selges i mange forskjellige butikker i forskjellige områder (CDN), så man alltid har mulighet til å få tak i dem med kort ventetid. Man kan være heldig å finne en lue i den fargen og størrelsen man ønsker som passer til tiltenkt bruk. Ulempen med disse er at de ikke kan tilpasses enkelt, og at det kan ta tid å lage alle de forskjellige modellene ved endringer.
Cloud Functions (Serverless functions) kan sammenlignes med en luestrikkende robot. Her lages luen etter kundens ønske etter bestillingen, og på den tiden man ikke har noen bestillinger inne har man heller ingen kostnad (On-demand). Ulempene med dette kan være at denne roboten er plassert kun ett sted, som kan føre til lang ventetid før man får luen man har bestilt (høy latency).
Så hva menes egentlig med “Edge Computing”?
For å ta en pause fra lue-analogien, kan man tenke at Edge Computing blir en kombinasjon av Cloud Functions og Content Delivery Network (CDN). For å få til dette kan deploye flere kopier av Cloud Functions på forskjellige servere rundt om i verden. Da kan man få fordelene ved Cloud Functions, med ventetiden til SSG. Dette kan tenkes som en lettere skalerbar versjon av SSR uten at man trenger å betale for tiden og ressursene man ikke bruker.
Better Living by Changing Less – IncrativeOps
Foredrag av: Michael Coté
(tekst: Lars Kåre Syversen)
Omtrent alle kan være enig i at CI/CD i et prosjekt kan spare drøssevis av tid du ellers ville brukt til manuell prodsetting. Mengden tid spart er helt avhengig av hvor ofte et prosjekt prodsettes. Statistikken viser at de fleste publiserer nye deployments under en gang i måneden. Med hvor mye tid CI/CD kan ta å sette opp i helt ferske prosjekter, hvor ofte må vi publisere for å faktisk spare tid i lengden? Byggeautomatisering har flatet ut over årene, mens automatisering av deployments går stadig oppover. Alle vet at det er bedre med automatisert bygging og deployment, men mange gjør det fortsatt ikke.
Change or die
I IT har vi en idé om at vi må bruke de nyeste teknologiene så fort som mulig for å holde seg oppdatert med konkurransen. Med mindre vi endrer måten vi jobber på, vil noen andre komme inn å ta over. De siste årene har det vist seg at mange av de nye teknologiene som kommer inn for å revolusjonere måten vi jobber på egentlig ikke har så mye å by på, og mange av de dør innen få år. Folk prater mye om AI, men få selskaper har faktisk gått inn for å benytte det. I alle år har man forventet at flytting av infrastruktur til sky er i ferd med å eksplodere, men i realiteten har det vært en sakte men sikker økning.
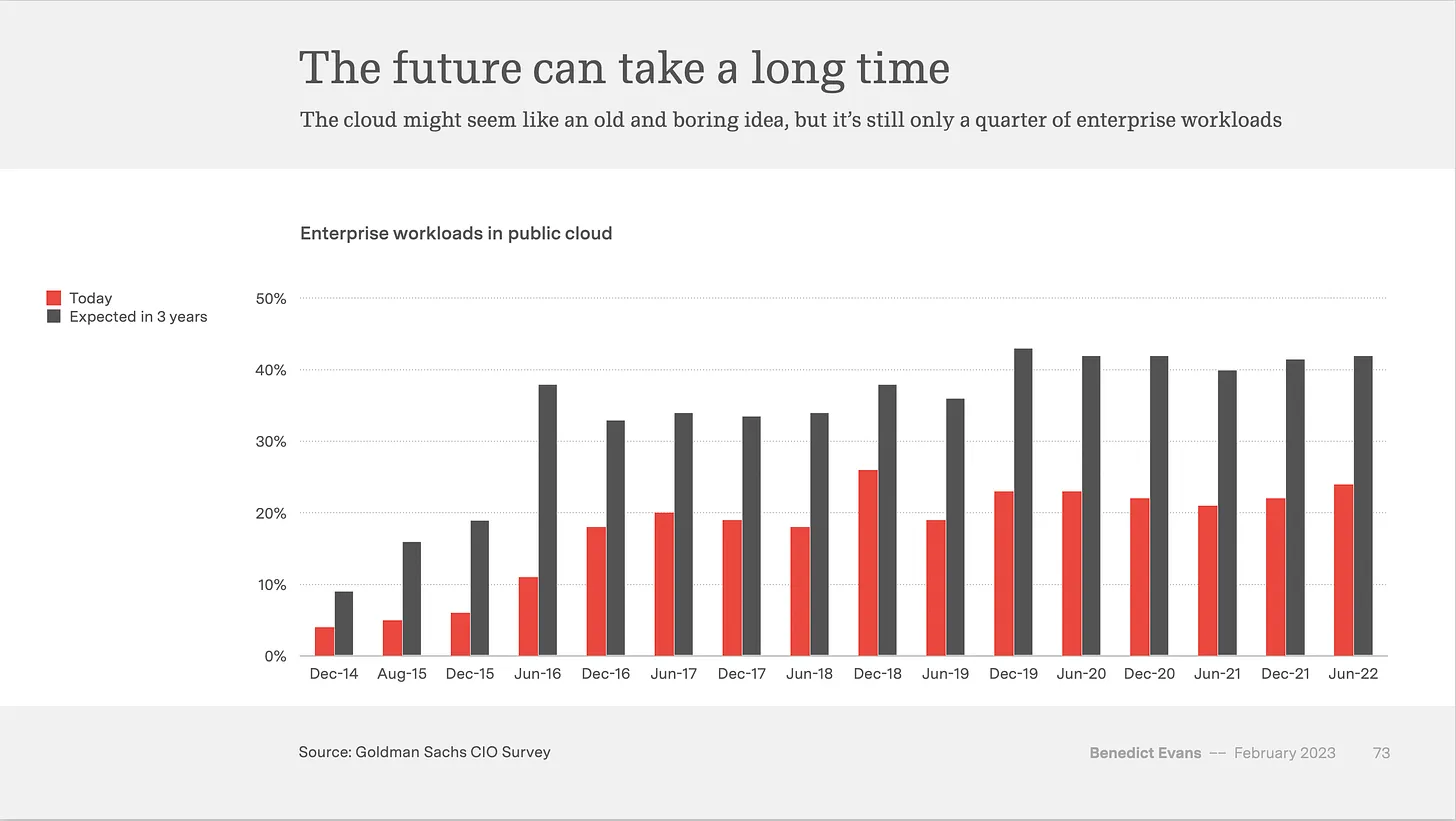
Hvorfor så tregt?
Å gå over til nyere teknologier er dyrt. Ofte er det veldig dyrt. Det skal mye arbeidskraft til for å flytte alt av on-prem løsninger over i sky. Sannsynligvis er det verdt det, men man vil gjerne være sikker på at de løsningene man går over til er der for å bli. Vi er redde for å potensielt gjøre bortkastet arbeid ved å være for tidlig ute med nye teknologier.
Nye teknologier
Man må for all del holde seg oppdatert på det nye og kule i teknologi-verdenen, men gjør det med omhu. Mange kaster bort tiden sin ved å bygge ut diverse “proof-of-concept” prosjekter som ikke er knyttet til noen faktisk verdi for bedriften. Dette er fordi du da beskytter deg mot potensielle skader dersom prosjektene skulle feile, men det betyr samtidig at du aldri faktisk tar i bruk teknologien på en slik måte at du kan lære fra den og forbedre den. Når du først bestemmer deg for å prøve ut noe nytt bør du gå inn på en måte som gir faktisk utbytte.
Konklusjon
Michael Coté forslår at vi som utviklere burde prioritere å bruke tid på det vi faktisk kan fremfor å transformere alt til det nyeste og beste, siden vi aldri vet helt hva som blir værende. Inkrementelle forbedringer av det vi faktisk gjør daglig er i følge Coté den beste bruken av tiden din, og kan både spare deg for bortkastet tid og forbedre dine vaner i de dagligdagse arbeidsoppgavene.
Utvidet opphold
 Foto: Christian Nyvoll
Foto: Christian Nyvoll
En fordel man kan velge å benytte seg når man reiser på konferanser, spesielt til spennende byer, er at man kan vurdere å utvide oppholdet sitt. Da benytter de ansatte én eller flere feriedager for å få mer tid til å oppleve stedet man har reist til, når man først har tatt turen. Det anbefales på det sterkeste å vurdere!
Vi var så heldige at Tormod bodde i Berlin tidligere, og med det hadde vi en lokalkjent turguide som på våre ekstra dager i Berlin kunne vise oss rundt på mesterlig vis. Været var fantastisk og vi fikk oppleve Berlin fra sin beste side, både til fots, med sykkel og kollektivtransport. Vi utforsket hva Berlin har å by på både på dag og natt, spennende mat og godt tysk øl.

Foto: Christian Nyvoll
Key takeways / fremhevede presentasjoner
Ta kontakt med en av oss deltakere dersom du ønsker slides fra noen av presentasjonen vi nevner her, eller de andre på programmet hos https://stackconf.eu/schedule/
Hovedkontakt: christian.nyvoll@knowit.no
Konklusjon
Å reise på konferanse med kolleger er en fantastisk måte å bli bedre kjent med ansatte i selskapet på, samtidig som man kan få verdifull faglig påfyll. Det er inspirerende å høre fra andre teknologer utenfor Norge hva som skjer, eller kanskje kommer til å skje innenfor teknologi i fremtiden. Vi sitter igjen med ett inntrykk av at det er mange positive ting ved å reise på en litt mindre konferanse, slik som Stackconf var med sine 150 deltakere, spesielt at det er enklere å komme i kontakt med andre deltakere når man ser de samme igjen i løpet av konferansedagene. Som man antagelig kan se fra bildene koste vi oss veldig på tur i Berlin, og vil definitivt anbefale det som konferansedestinasjon!




